
In an era where large language models (LLMs) are influencing everything from legal documents to medical advice, how do we know if we can trust their outputs? Enter DeepEval — a Pytest-style framework for testing LLMs like you would test code.
What is DeepEval?
Developed by the team at Confident AI, DeepEval is an open-source framework that brings unit testing principles to language model evaluation. It enables researchers and developers to write structured, reproducible tests for LLMs, using modern NLP metrics as pass/fail conditions. Think of it like Pytest meets ChatGPT.
The tool has been gaining traction since its late 2023 launch, especially after a major update in early 2024 introduced broader metrics, dashboard support, and integration for synthetic test generation.
“If LLMs are going to become digital coworkers, we need to give them performance reviews.” — Nick Hubchak AI Engineer
Why It Matters: The Problem With Current LLM Evaluation
Most developers still evaluate models using:
- A few ad hoc prompts
- Manual grading or gut feeling
- Outdated static benchmarks
This doesn’t scale — and worse, it doesn’t reveal critical issues like hallucinations, bias, or poor reasoning.
DeepEval addresses this by letting you:
- Define what “good output” means using test assertions.
- Use research-backed metrics like G-Eval, ROUGE, and truthfulness checks.
- Run test suites as part of your CI/CD pipeline.
How DeepEval Works (No Code Needed)
At its core, DeepEval organizes each test around:
- Prompt: What you give the model
- Expected behavior: The correct or acceptable response
- Evaluation metric: How you determine if the output passes
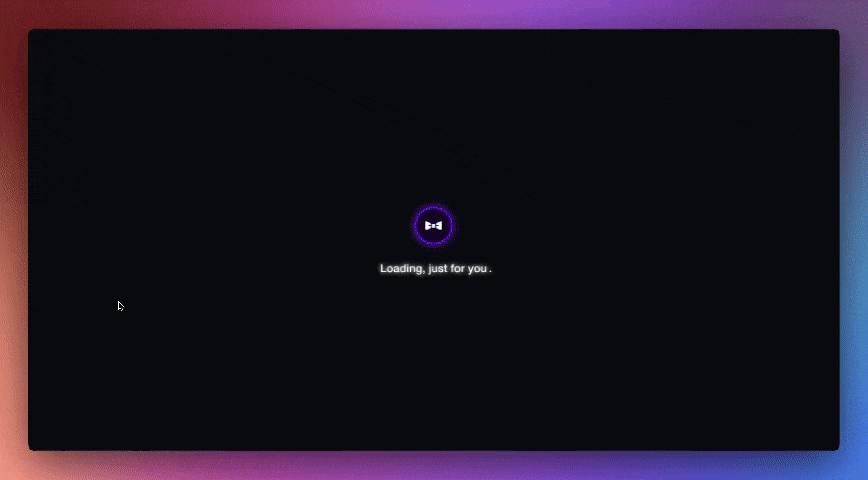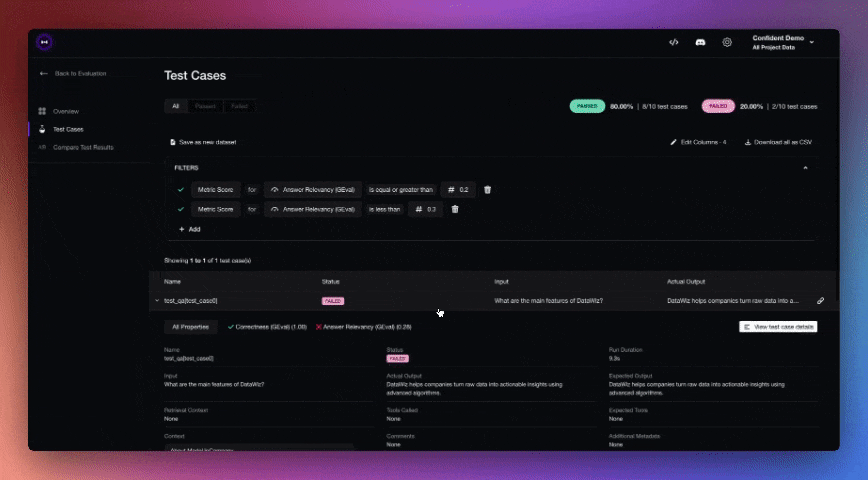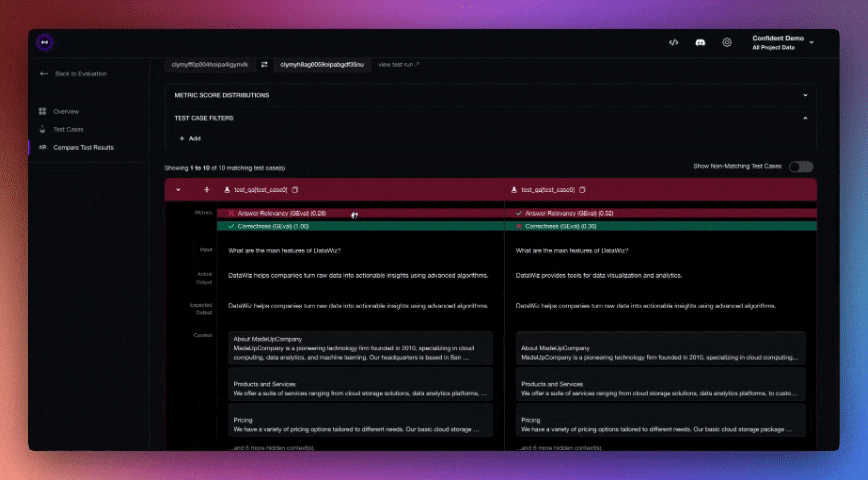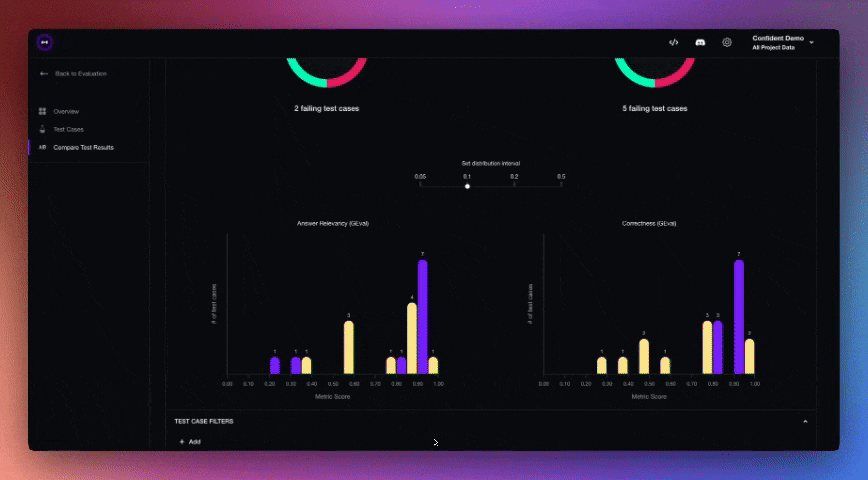
You define these using decorators like @deepeval_test, and then run tests using Pytest. The output is a clean report showing what passed, what failed, and why.
Bonus: You can even create synthetic test cases on the fly, generating new test prompts to probe edge cases or model failure modes.
Real-World Use Cases
Here’s how different teams could leverage DeepEval:
- Legal tech: Test if your AI summaries of contracts ever insert non-existent clauses.
- Healthcare: Confirm that medical advice doesn’t hallucinate treatment plans.
- Research: Benchmark new LLMs against existing models using fairness or truthfulness tests.
This turns LLM evaluation from guesswork into a reproducible science.
What Makes DeepEval Unique?
- ✅ Works with OpenAI, HuggingFace, and custom APIs
- ✅ Over 14 metrics including G-Eval, factuality, bias, and more
- ✅ Pluggable: You can define your own metrics or behaviors
- ✅ Open source and rapidly evolving
Compared to tools like LM Eval Harness or TruthfulQA, DeepEval feels more interactive, composable, and developer-friendly.
Limitations to Know
DeepEval isn’t perfect:
- It still requires API keys for commercial models like GPT-4
- Some metrics lack interpretability (“why” a test failed isn’t always obvious)
- Synthetic generation works best when tuned carefully
That said, the roadmap includes integrations for SHAP explanations and real-time error visualizations.
The Future of LLM Evaluation?
Tools like DeepEval are setting a new standard for what LLM testing should look like. As language models continue to shape decision-making systems, evaluation frameworks must evolve too.
Whether you’re building the next Claude or deploying a fine-tuned LLaMA-3, DeepEval offers a bridge between software rigor and language intelligence.
Try It Yourself
DeepEval is open-source and available on GitHub: https://github.com/confident-ai/deepeval
Docs and demo: https://docs.confident-ai.com/deepeval
All images are from DeepEval. Big shoutout to the team over at DeepEval with their great work and blog, thank you!
If you’re serious about building safe and effective LLMs, give it a spin — and maybe even write your models a few tests.
Leave a Reply